DeepSentiPers: Novel Deep Learning Models Trained Over Proposed Augmented Persian Sentiment Corpus
Abstract
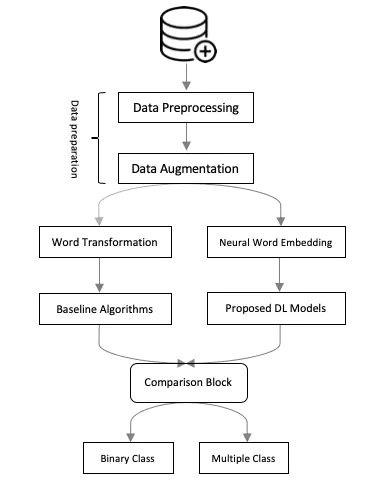
This paper focuses on how to extract opinions over each Persian sentence-level text. Deep learning models provided a new way to boost the quality of the output. However, these architectures need to feed on big annotated data as well as an accurate design. To best of our knowledge, we do not merely suffer from lack of well-annotated Persian sentiment corpus, but also a novel model to classify the Persian opinions in terms of both multiple and binary classification. So in this work, first we propose two novel deep learning architectures comprises of bidirectional LSTM and CNN. They are a part of a deep hierarchy designed precisely and also able to classify sentences in both cases. Second, we suggested three data augmentation techniques for the low-resources Persian sentiment corpus. Our comprehensive experiments on three baselines and two different neural word embedding methods show that our data augmentation methods and intended models successfully address the aims of the research.